Skip to content
Deals
Newsletter
Launch on RocketHub
Marketplace
Marketplace Deals
Why List with Us
How It Works
Marketplace Giveaway
FAQs
Exclusive vs Marketplace
Blog
Menu
Deals
Newsletter
Launch on RocketHub
Marketplace
Marketplace Deals
Why List with Us
How It Works
Marketplace Giveaway
FAQs
Exclusive vs Marketplace
Blog
Deals
Black Friday Deals
Launch on RH
Marketplace
Marketplace Deals
Why List With Us
How It Works
Marketplace Giveaway
Marketplace FAQs
Exclusive vs Marketplace Deals
Blog
Menu
Deals
Black Friday Deals
Launch on RH
Marketplace
Marketplace Deals
Why List With Us
How It Works
Marketplace Giveaway
Marketplace FAQs
Exclusive vs Marketplace Deals
Blog
$
0.00
0
Cart
Exclusive Deals
MySEOAuditor
Rated
4.83
out of 5 based on
6
customer ratings
(6) Reviews
$
59.00
–
$
249.00
Select options
StoreGrowth
Rated
5.00
out of 5 based on
1
customer rating
(1) Reviews
$
39.00
–
$
149.00
Select options
SEOPilot AI Writer (SaaS)
Rated
4.00
out of 5 based on
2
customer ratings
(2) Reviews
$
99.00
–
$
349.00
Select options
Izyu
Rated
5.00
out of 5 based on
1
customer rating
(1) Reviews
$
59.00
–
$
249.00
Select options
SEOPilot Chrome Extension
Rated
5.00
out of 5 based on
2
customer ratings
(2) Reviews
$
49.00
Select options
LeadBites Funded Startups List
Rated
5.00
out of 5 based on
3
customer ratings
(3) Reviews
$
299.00
–
$
499.00
Select options
Leadinary
Rated
4.00
out of 5 based on
4
customer ratings
(4) Reviews
$
79.00
–
$
699.00
Select options
Eariously
Rated
5.00
out of 5 based on
1
customer rating
(1) Reviews
$79 - $1499
Select options
Header Footer Code Manager Pro WordPress Plugin
Rated
5.00
out of 5 based on
11
customer ratings
(11) Reviews
$
29.00
–
$
119.00
Select options
The Worlds Biggest Encyclopedia of the Top 977 Growth Hacks
Rated
5.00
out of 5 based on
1
customer rating
(1) Reviews
$
69.00
Add to cart
Content Craft Social Calendar
Rated
4.00
out of 5 based on
8
customer ratings
(8) Reviews
$
27.00
Add to cart
Content Craft Caption Catalog
Rated
4.56
out of 5 based on
9
customer ratings
(9) Reviews
$
37.00
Add to cart
300 Facebook Ads That Are Killing It! [Curated & Critiqued by Elite Advertisers]
Rated
5.00
out of 5 based on
2
customer ratings
(2) Reviews
$
27.00
Add to cart
Marketplace Deals
SIR
Rated
0
out of 5
(0) Reviews
$36.99
Add to cart
Learnitive
Rated
0
out of 5
(0) Reviews
$
49.00
Select options
Protected: Documenter
Rated
0
out of 5
(0) Reviews
$49.00
Add to cart
Voicely
Rated
0
out of 5
(0) Reviews
$69.00
Add to cart
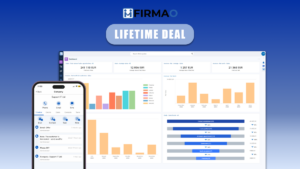
Firmao CRM
Rated
0
out of 5
(0) Reviews
$1596.00
Add to cart
Vidtoon
Rated
0
out of 5
(0) Reviews
$49.00
Add to cart
iSend Professional
Rated
0
out of 5
(0) Reviews
$59.00
Add to cart
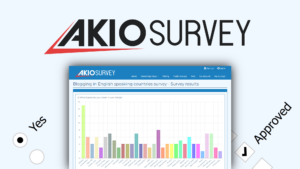
AkioSurvey
Rated
0
out of 5
(0) Reviews
$89.00
Add to cart
AffSync
Rated
0
out of 5
(0) Reviews
$89.00
Add to cart
View Marketplace
Info Products
Podcast Outreach System
Rated
0
out of 5
(0) Reviews
$
17.00
Add to cart
How to Increase Sales on Amazon
Rated
0
out of 5
(0) Reviews
$
17.00
Add to cart
Highly Effective Facebook Ads Strategies for Your Amazon Business
Rated
0
out of 5
(0) Reviews
$
17.00
Add to cart
Facebook Groups: Top Paid Growth Strategies (Coaches Edition)
Rated
0
out of 5
(0) Reviews
$
37.00
Add to cart
Instagram Influencer Marketing Kit
Rated
5.00
out of 5 based on
1
customer rating
(1) Reviews
$
27.00
Add to cart
Previous Exclusive Deals
SOLD OUT
PageNudge
$
39.00
–
$
199.00
Select options
SOLD OUT
SOLD OUT
Link Sourcery
$
79.00
–
$
699.00
Select options
SOLD OUT
SOLD OUT
SOLD OUT
Elai
$
99.00
–
$
999.00
Select options
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
FluxForms
$
49.00
–
$
129.00
Select options
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
Leadzilla
$
99.00
–
$
599.00
Select options
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
Pause
$
199.00
–
$
899.00
Select options
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
Getflix.com
$49.00
View More
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
OpenMyLink
$49
View More
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
Upscale
$
199.00
–
$
699.00
Select options
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
Record
$
69.00
–
$
249.00
Select options
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
Magai
$
99.00
–
$
399.00
Select options
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
SOLD OUT
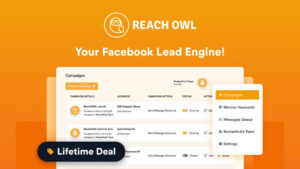
ReachOwl
$
49.00
–
$
499.00
Select options